"내 북 위시 리스트 속 책의 제목에 가장 자주 등장하는 단어는 뭘까?"
이 질문은 그 사람을 얼마나 드러낼까요? 이번 소프로젝트의 결과를 보면 알 수 있을 것 같습니다.
위시리스트 목록 받아오기
일단 알라딘 보관함에서 리스트를 엑셀로 저장해옵니다. 캡쳐 당시엔 보관함에 331개의 책을 넣어두었습니다! 항상 느끼지만 세상은 넓고 인생은 짧고 갈 곳은 많고 읽을 책은 많은 것 같아요.
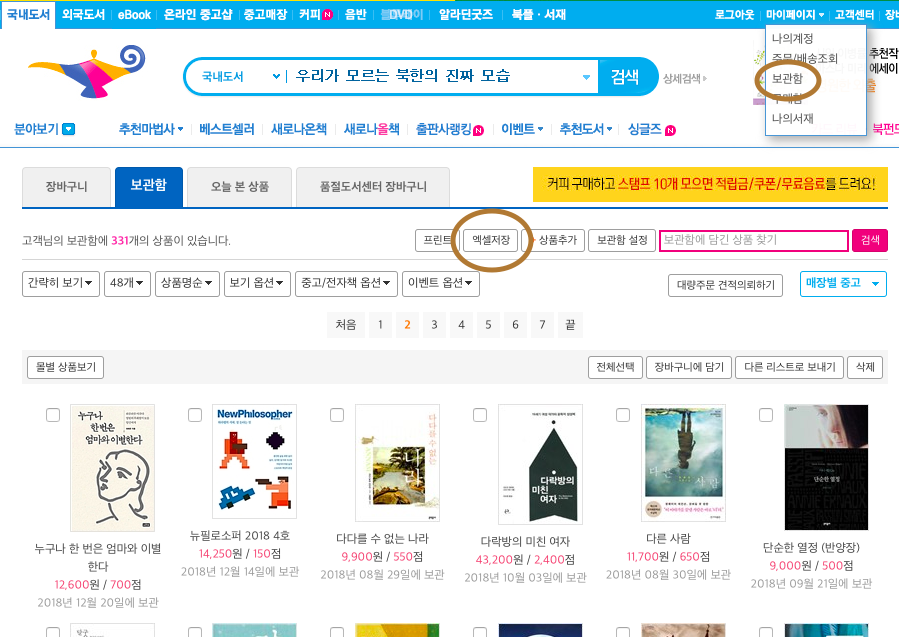
알라딘에선 보관함의 책 리스트를 '.xls'파일로 제공하고 있는데 이 확장자는 R에서 지원을 하지 않는 듯 해서, save as를 이용해 확장자를 '.xlsx'로 바꿔주었습니다. 유니코드 인코딩 문제로 한글이 깨지길래 xlsx 파일을 사용했습니다. (이제 막 시작했는데 야매의 기운이 넘쳐흐릅니다. 데이터분석 초보의 사이드프로젝트라는 점 이해해주세용)
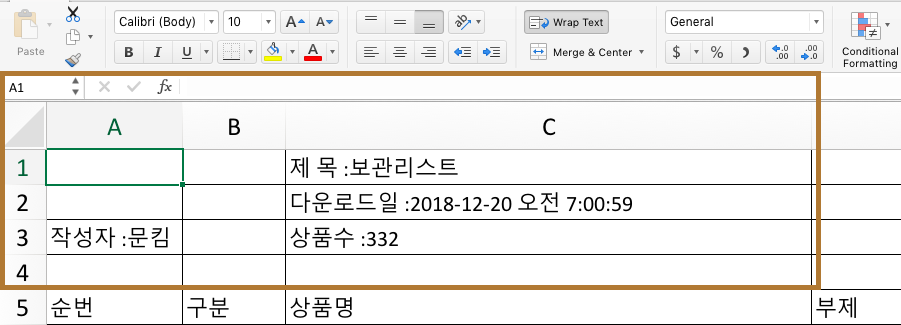
데이터 가공
엑셀 파일을 열면 이런식으로 간소한 설명이 적혀 있습니다. 분석을 쉽게 하기 위해(첫 열을 header로 자동 지정하기 위해) 엑셀 자체에서 1,2,3,4열을 지웠습니다.
#엑셀 파일 불러올 패키지 불러오기
install.packages('readxl')
library('readxl')
book <- read_excel('bookwish.xlsx') #분석할 엑셀 파일을 불러오기 (워킹 디렉토리로부터)
copy <- book #카피본 만들어두기
dim(book) #엑셀 파일이 335행, 22열로 이루어졌음을 알 수 있다.
#column 1,2,6,8,13,15,19,20 삭제 (분석하지 않을 요소들!)
book <- book[,-c(1,2,6,8,13,15,19,20)] #column을 삭제한 데이터프레임을 다시 씌워주는 개념
dim(book) #335행, 14열로 줄어들었음을 확인
#영어로 변수명 바꿔주기
install.packages('dplyr')
library('dplyr')
book <- rename(book,
title = 상품명,
series = 시리즈명,
subtitle = 부제,
isbn = ISBN,
publisher = 출판사,
author = 저자,
price = 정가,
dprice = 판매가,
dpercentage = 할인율,
pdate = 출간일,
style = 판형,
field = 분야,
page = 페이지수,
meh = 부가기호)
셀 제목들이 한국어로 되어있는데 영어로 해야 코딩할 때 쉬울 것 같아서 영어로 이름을 바꿔주었습니다.
필터링
#style(판형) 이 NA(결측치)인 E-book 제거
table(is.na(book$style)) #결측치 몇개 있나 table로 만들어서 확인
book <- book %>% filter(!is.na(style))
이북도 8권 정도가 포함되어 있었는데, 아쉽지만 판형을 기준으로 그냥 다 빼버렸습니다.
#텍스트 마이닝 패키지 설치
install.packages('rJava')
install.packages('memoise')
install.packages('KoNLP')
library(KoNLP)
library(dplyr)
useSejongDic()
#책 제목에 들어간 특수문자 제거하기
install.packages('stringr')
library(stringr)
이번 소프로젝트에서는 책 타이틀 column만 있으면 돼서 책 제목만 모아서 txt 파일을 만들어 그걸로 분석했습니다.
명사 추출과 빈도수 정렬
#명사 추출
install.packages('extractNoun')
nouns <- extractNoun(title) #제목의 명사만 추출한 데이터 만들어준다.
wordcount <- table(unlist(nouns)) #추출한 명사 리스트를 문자열 벡터(?)로 변환, 단어별 빈도표 생성
word <- as.data.frame(wordcount, stringsAsFactors = F)
word <- rename(word,
word = Var1,
freq = Freq) #정갈하게 데이터프레임 변수명 바꿔주기
df_word <- filter(word, nchar(word) >= 2) #2글자 이상 단어 추출
그 다음엔 단어(명사)목록과 등장 횟수를 표로 정리하고, 탑 20을 빈도수로 정렬했습니다.
이렇게 하고 나면...
대망의
뚜둥
이런 결과가 나옵니다⭐️
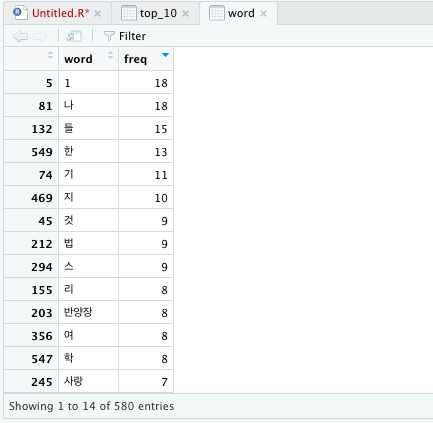
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
1이요??? 조금 갑작스럽군요
사실 이게 진짜_최종_데이터분석_결과는 아니고,
'2글자 이상의 단어'라는 조건을 지정해주기 전의 raw data라고 보면 됩니다.
그래서 진짜 top 20를 보면
짜잔!
결과
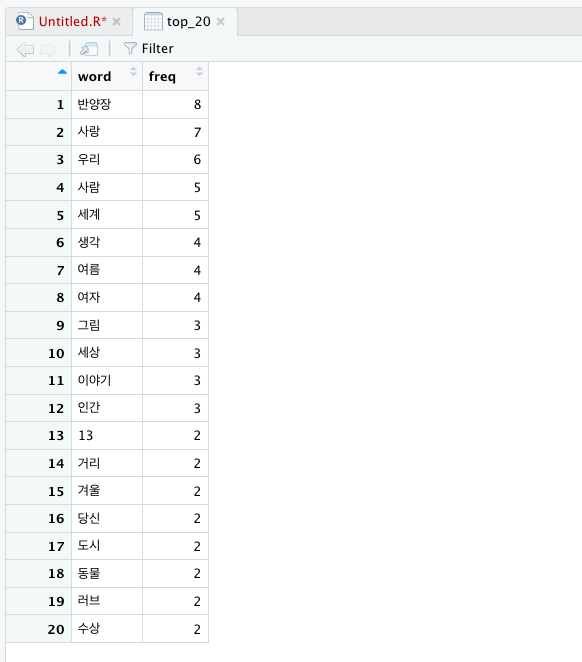
1위 '반양장'
그럴수도있는거잖아요 한국인이라면페이퍼백보다양장반양장제본을더좋아할수도있는거잖아요반양장이라는단어가1위할수도 있는거잖아요솔직히반박할수는없는거잖아요
데이터 분석을 한번에 쉽게 후루룩 한게 아니고 막힌 부분들도 많았는데 저런 유쾌한 결과가 나오니까 재미있었습니다. 뿌듯하기도 했고요!
2위 '사랑'
반양장 제외 1위인 '사랑'이라는 단어는 꽤 예측 가능했는데요 왜냐면 이 프로젝트를 할 당시의 저는 꽤나 감성적이었기 때문입니다!!!
그 다음으로 '우리', '사람'.. 이런 결과가 많이 나왔습니다. 알라딘 위시리스트에 담아두는 책은 어렸을 때부터 꾸준히 담아온 것들이라 인간에게 관심이 많은 특성이 잘 드러나는 것 같아요. 책을 꽤 편식해서 읽는구나 하는 생각도 들었네요. (이 질문에 대한 답은 책 분야편에서 찾을 수 있습니다)
3위 '우리', '사람', '세계'...
결론: '내 북 위시 리스트에 가장 자주 등장하는 단어가 뭘까?'라는 질문은 당신을 설명해주는 일종의 리트머스 시험지가 될 수 있습니다!